
Hoy les hablaré de epidemiología. Y de confianza. Pero no de la que creen. O si. Y de cómo medirla.
Son tiempos simplistas. Todo tiende a simplificarse. No nos gusta la incertidumbre ni los grises. Demandamos dicotomías. Blanco o negro. Déjeme ud. de grises. NECESITO que sea o una cosa o la otra. Deme certezas, y démelas ahora. Es lo que hay. Y como casi nunca las damos, somos muy malos.
He pensado que igual conviene hablar un poco de confianza. En epidemiología se trata un poco de eso. Casi nada es seguro 100%. Se trabaja con la confianza. O con cómo de confiable es un resultado. Cuánto podemos fiarnos de eso de lo que hablamos. Prometo mensajes sencillos.
Hay un concepto clave en esto y que a menudo no se entiende bien o simplemente se ignora. Se llama intervalo de confianza. Y este pequeño hilo va de eso.
Antes una mini introducción sobre conceptos muy básicos.
Fijaos, a menudo leemos titulares, notas de prensa (muchas) e incluso estudios, en los que se habla de pacientes o personas que han sido estudiadas para investigar sobre algo en concreto. Sé que todos estáis pensando en las vacunas de la #covid19 ahora… Pero #notodoesCovid.
Pensad una cosa: si hay un estudio que concluye tal cosa, ese estudio ha considerado un número limitado de pacientes. Por ejemplo, en los trabajos sobre efectividad de las vacunas, estamos viendo que se incluyen (por suerte) miles y miles de pacientes ¿verdad?
Pero aún así, ¿creéis que son todos todos los que se podían incluir? NO. Y hay muchos motivos por los que esto no puede ser. Siempre voy a dejarme a alguien.
Otro ejemplo, si hago un estudio para ver de qué efecto tiene un determinado medicamento en la evolución de cierta enfermedad, ¿creéis que aun en el mejor de los casos voy a poder considerar a absolutamente todos los pacientes que tienen esa enfermedad? Obviamente NO.
Bien, pues a groso modo, todos los pts con esa determinada enfermedad, pero que por un motivo u otro, no están en mi estudio, serán la POBLACIÓN de estudio. Y aquellos que finalmente si han formato parte de mi estudio serán mi MUESTRA de estudio. Son personas ‘seleccionadas’ para participar o conformar mi estudio, que tiene el objetivo que sea.
¿Bien?
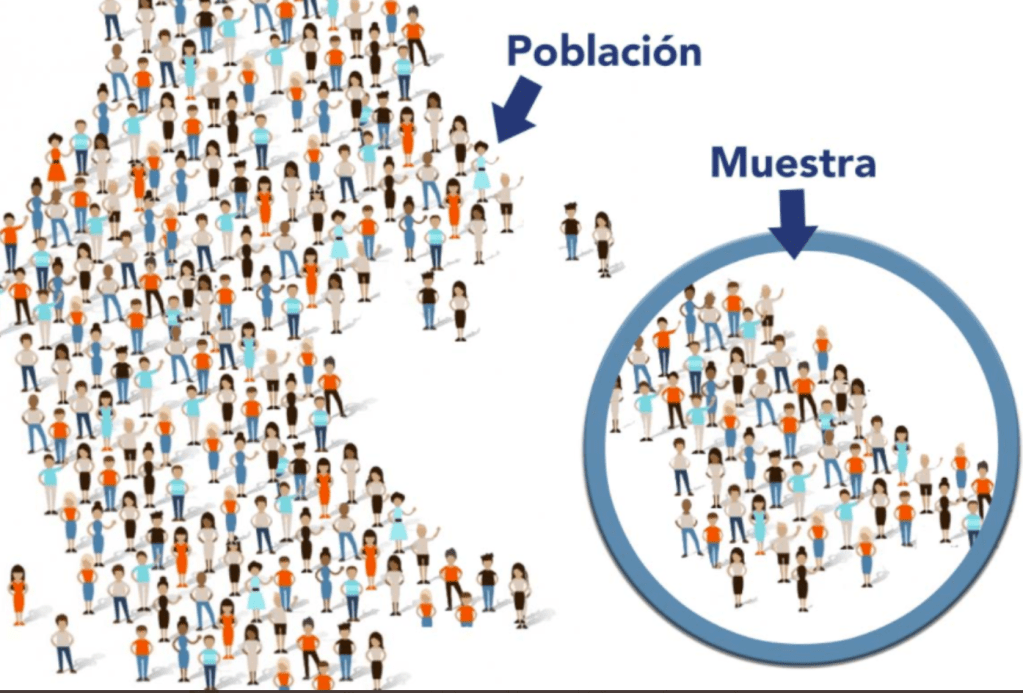
Y es en esas personas a las que yo tengo acceso y he incluido, en las que voy a medir o a estudiar características determinadas y que naturalmente varía entre ellas (variables) ¿si?
En esencia, en esto consiste la investigación. Al final, esas características han de ser resumidas, observadas de forma global, y finalmente tomadas para extraer unas conclusiones.
¿Qué problema tenemos entonces?
[Esto es simplificar mucho OJO, con fines divulgativos lo contamos así]
Pues que como hemos dicho antes, esas conclusiones, realmente están siendo enunciadas en base a los pacientes que yo he considerado en mi estudio. Pero claro, NO de TODOS los pacientes a los que podía haber tenido en cuenta.
Trabajar con muestras no tiene porqué ser un grave problema, pero hay que pagar un precio: el error de muestreo, un error que depende de la influencia del azar (por eso también se llama error aleatorio) y que en términos prácticos se traduce en la imprecisión de las estimaciones.
Aquí lo explicaba con más detalle
Cuanto más pequeña es la muestra, mayor es el posible error de muestreo, mayor es la posibilidad de que el azar explique el resultado, y, en consecuencia, mayor es la imprecisión.
Tsss, decepción… SPOILER: Aquí es donde los lumbreras que ahora se han montado al chiringuito negacionista manipulan cuando les interesa…
¿Qué se hace entonces? Fijaos, hay una cosa que se llama INTERVALO de CONFIANZA.

Antes, una pequeña puntualización.
Cuando estamos midiendo características de los pacientes o personas que estamos estudiando, podremos hacerlo con aquellas que están definidas numéricamente, por ejemplo, la edad de alguien, 30, 20, 87… años. Otras veces, estaremos midiendo cosas como el tener por ejemplo la tensión arterial alta. En este caso anotaríamos que SI la tiene (si es así) o que NO la tiene ¿se entiende? Es fácil. Son ‘variables’ de otro tipo, que nos cuentan cosas de esa persona, pero que no podemos registrar con un número, como la edad.

Pues bien, centrémonos en detalles o características de la gente que podemos cuantificar o comunicar con un número, por ejemplo la edad. Tenemos en epidemiología un concepto que se llama ‘parámetro’ y otro denominado ‘estadístico’. Tirando de nuestro ejemplo, el 1º hace alusión a la edad promedio de todos las personas que podríamos haber incluido en nuestro estudio (Friendly reminder: o ‘población de estudio’) y el 2º a la edad de las que SI hemos incluido (‘muestra de estudio’). Y hay otra cosa un poco compleja que se llama INFERENCIA, que son técnicas que nos permitirán estimar el valor de un parámetro a partir del valor de un estadístico.

Esta estimación puede ser puntual o bien por intervalo. La mejor estimación puntual de un parámetro es simplemente el valor del estadístico correspondiente, pero es poco informativa porque la probabilidad de no dar con el valor correcto es muy elevada, así que es por eso que se acostumbra a dar una estimación por intervalo, en el que se espera encontrar el valor del parámetro con una elevada probabilidad. Esta estimación recibe el nombre de estimación mediante intervalos de confianza.
Pues bien, la estimación por intervalos de confianza consiste en determinar un posible rango de valores o intervalo (a; b), en el que, con una determinada probabilidad, sus límites contendrán el valor del parámetro poblacional que andamos buscando. Para cada muestra obtendremos un intervalo distinto que, para el X % de ellas, contendrá el verdadero valor del parámetro. A este intervalo se le denomina intervalo de confianza.
Por último, a la probabilidad de que hayamos acertado al decir que el intervalo contiene al parámetro se la denomina nivel de confianza, y habitualmente se fija en un 95%. En otras palabras, El IC nos indica el intervalo de valores en el que se encontrará el valor del parámetro estimado en la población de la que deriva la muestra en la que se ha hecho el estudio, con un grado razonable de confianza.
De forma sencilla, si tuviéramos la oportunidad de realizar el mismo estudio 100 veces, del mismo modo, y calculáramos para cada uno de ellos el IC95%, tendríamos que 95 de ellos incluirían el valor poblacional y 5 no. O también, nos permite estimar entre qué valores está el valor inaccesible real de la población a partir del que podemos obtener de nuestra muestra, con una probabilidad de equivocarnos del 5%.
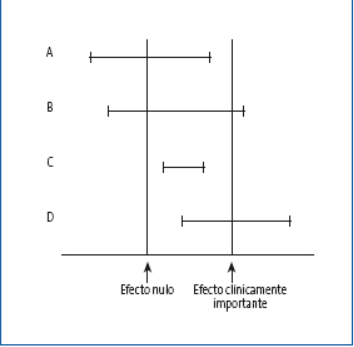
De forma general, cuanto más estrecho sea dicho intervalo, más precisa será la medida. Y un pequeño truco, si vamos a comparar una variable entre por ejemplo dos grupos distintos de pacientes, se calcula el IC y vemos que dicho intervalo incluye el valor 0 o nulo, NO FIAROS. El mero azar puede estar confundiendo ese resultado. No haría falta ni siquiera ver el valor p (SI, sé que alguno en este punto ya se está tirando de los pelos porque no he hablado de los dichosos valores p).
Apunte #COVID19: Esto es especialmente útil en estos días, donde hay tanto artículo circulando en el que se comparan cosas entre vacunados y no vacunados, un tratamiento frente a otro, etc. Fijaos en el IC. Si es muy amplio, desconfiad insensatos.
pD. OJO, he hecho muchas asunciones y omitido muchas cosas, porque se salen del fondo divulgativo del hilo. He puesto como ejemplo la edad, pero los IC se pueden calcular de otras medidas como proporciones, etc. Hay fórmulas para ello y programas. La idea no era esa.
Espero se haya entendido
Como siempre, si han llegado hasta aquí, el mérito no es mío sino suyo
Hasta otra
Fuentes:
https://www.elsevier.com/books/bioestadistica-amigable/martinez-gonzalez/978-84-9113-407-7
https://www.cdc.gov/eis/field-epi-manual/index.html

Deja un comentario